「メッセージ」テーブルのフィールド定義
インターネットの掲示板やメールアプリケーションで、「コメントチェーン」に従ったメッセージの表示やトレースの機能が見られます。あるメッセージに対して誰かが返信すると、それが返信と分かるように、直下の行にインデントをかけて表示するといったものです。コメントのコメントが作られると、さらにインデントされて表示するといった感じです。議論の流れが順番に分かるなどのメリットがあるため、比較的よく見られるようになりました。FileMakerでこのコメントチェーンを実現する方法はいろいろあるでしょうけど、決して簡単なものではありません。しかしながら、ある程度の制約下で実現する事は可能です。ここでは、リレーションの機能を使った方法を説明しますが、まず始めにFileMakerとは無関係にリレーショナルデータベースという仕組みの上で、コメントチェーンをどう処理するのかということをまとめ、それをFileMakerで実現する方法を説明します。
掲示板的なアプリケーションがあるとして、まずは基本的なスキーマを考えるとします。おそらく誰もが、「1メッセージ=1レコード」という設計を思い付くでしょう。もちろん、他にやりようがありませんが、フィールドとしては、「メッセージ内容」「タイトル」「作成者」「書き込み日付」などなどが思い付きます。これらメッセージの内容を管理するフィールドは自由に設計してもいいわけですが、ここでは特定の用途は想定しないで、以下のフィールドがあるものとします。ごく基本的なメッセージ管理です。
| フィールド名 | タイプ | 用途 |
|---|---|---|
| id | 数値 | オプションで自動的に連番を振る。キーになるフィールド |
| タイトル | 文字列 | メッセージのタイトル |
| メッセージ | 文字列 | メッセージの内容 |
| 作成日時 | タイムスタンプ | 自動的にレコード作成日時を入力 |
コメントチェーンを管理する事になるとします。そうすると、まずは「自分のコメント先のメッセージ」を何とか記録しておくのがいいのじゃないかと考えるわけです。つまり、コメントを付ける元になったメッセージの「id」フィールドを記録するということになります。これであとはなんとかレイアウトを考えて…というのがFileMaker的な方法ではありますが、これだけだとどうこねくり回してもうまく行かないと普通は考えるでしょう。コメント先やコメントされているメッセージの検索はできますが、ポイントとなるのはコメントは何段階になっているかは一定ではないということです。まったくコメントのないメッセージもあるし、10段階にコメントされている場合もあるかもしれません。プログラミングの世界だと、順番にたどるようなプログラムを書けばいいということになるかもしれませんが、FileMakerのスクリプトではちょっと厳しいでしょう。
そこで、コメントチェーンのリストとしてレコードを並ばせるための「順序数」という情報を、フィールドとして記録する事を考えます。言い換えれば、最終的にこの「順序数」に従って並べ替えをすると、コメントチェーンの一覧として見えるというようなデータを、メッセージごとに記録しておくのです。レコードを作成するときにこの順序数をある規則で求めることになります。そして、メッセージを以下のようなフィールドで管理するものとします。順序数を求めるときにレベルなどの数値を記録しておく必要があり、結果的に、「順序数」「parent_id」「レベル」の3つのフィールドを追加することになります。
| フィールド名 | タイプ | 用途 |
|---|---|---|
| id | 数値 | オプションで自動的に連番を振る。キーになるフィールド |
| 順序数 | 数値 | 順序数を入れるフィールド |
| parent_id | 数値 | コメント元のメッセージのidの値。トップレベルだと空欄 |
| レベル | 数値 | 階層の深さを1以降の整数で記録 |
| タイトル | 文字列 | メッセージのタイトル |
| メッセージ | 文字列 | メッセージの内容 |
| 作成日時 | タイムスタンプ | 自動的にレコード作成日時を入力 |
ただ、順序数なら、1、2、3…などと指定していて、4と5の間にメッセージを入れたくなったらどうするの?と思われるでしょう。5以降を1ずつ増加するのもあるかもしれませんが、ここで発想をやや転換します。いきなり数学的なことを説明するのではなく、具体的な例で説明をしましょう。
「順序数」というと1ずつ増やしたくなるでしょうけど、とびとびの数値を使うと考えてください。ここでは分かりやすくするために、1000ずつとびとびの値をつけるような状況を考えます。メッセージ0からの動作はやや考えどころがあるので、ある程度のメッセージが入った状態から、コメントを付けたり、新たにトップレベルのメッセージを追加するということを考えます。まず、次のように3つのメッセージがあったとして、すべてがトップレベルのメッセージだったとします。順序数として、1000、2000、3000となっています。
| id | 順序数 | parent_id | レベル | タイトル |
|---|---|---|---|---|
| 1 | 1000 | 1 | 新バージョンはいつですか? | |
| 2 | 2000 | 1 | 納期延長のご相談 | |
| 3 | 3000 | 1 | インフルエンザで寝込んでいます… |
ここからいくらかメッセージを追加した状態のレコードを示します。どういう処理をしたかはさておいて、「順序数」フィールドに注意をしてください。新しいメッセージを追加しても、既存のメッセージの「順序数」は変更しないのを原則とします。id=4〜8の5つのメッセージを追加しました。それぞれコメント元がどれかはフィールドを参照してください。「順序数」でソートされていて、それによりコメントチェーンに従った順序になります。タイトルはコメントの関係が分かりやすいように、コメントのレベルに応じて頭にスペースを入れてインデントっぽく表示します。「順序数」にどんな数値を入れるべきかが問題ではありますが、ここではともかくこうなっているとしてください。
| id | 順序数 | parent_id | レベル | タイトル(レベルに応じたインデント付き) |
|---|---|---|---|---|
| 1 | 1000 | 1 | 新バージョンはいつですか? | |
| 4 | 1500 | 1 | 2 | Re-新バージョンはいつですか? |
| 5 | 1750 | 1 | 2 | Re-新バージョンはいつですか? |
| 8 | 1822 | 5 | 3 | Re-Re-新バージョンはいつですか? |
| 6 | 1875 | 1 | 2 | Re-新バージョンはいつですか? |
| 2 | 2000 | 1 | 納期延長のご相談 | |
| 7 | 2500 | 2 | 2 | 納期延長のご相談 |
| 3 | 3000 | 1 | インフルエンザで寝込んでいます… |
この状態から新たにコメントを加える状況を考えながら、順序数をどのように求めればいいかを考えてましょう。大きく分けて、コメントと、トップレベルのメッセージで方法論は大きく変わります。まずはコメントから考えます。
まず、id=1にコメントを付ける場合を考えてみましょう。コメントについては、そのコメントのレベル(この場合は2)と同じレベルのメッセージのうち、最後に付けるのが一般的です。なので、この場合、id=6とid=2のレコードの間に配置したい訳です。順序数としては1875〜2000の適当な数値の値を入れたい訳です。ここで、割り込む場所が決まった後に順序数を決めるルールとして、2つのメッセージの順序数のおおよその中間値をとる事にします。この求め方もいろいろ考えるところですが、簡単にするために中間値とします。次のメッセージは、id=9です。このレコードを追加し、「順序数」フィールドでソートすると、次のようになります。
| id | 順序数 | parent_id | レベル | タイトル(レベルに応じたインデント付き) |
|---|---|---|---|---|
| 1 | 1000 | 1 | 新バージョンはいつですか? | |
| 4 | 1500 | 1 | 2 | Re-新バージョンはいつですか? |
| 5 | 1750 | 1 | 2 | Re-新バージョンはいつですか? |
| 8 | 1822 | 5 | 3 | Re-Re-新バージョンはいつですか? |
| 6 | 1875 | 1 | 2 | Re-新バージョンはいつですか? |
| 9 | 1942 | 1 | 2 | Re-新バージョンはいつですか? |
| 2 | 2000 | 1 | 納期延長のご相談 | |
| 7 | 2500 | 2 | 2 | 納期延長のご相談 |
| 3 | 3000 | 1 | インフルエンザで寝込んでいます… |
id=8のメッセージにコメントを付けたとしましょう。次のレコードはid=10ですが、id=8とid=6のメッセージの間に割り込ませたいと考えます。すると、順序数としては1848くらいでしょうか。
| id | 順序数 | parent_id | レベル | タイトル(レベルに応じたインデント付き) |
|---|---|---|---|---|
| 1 | 1000 | 1 | 新バージョンはいつですか? | |
| 4 | 1500 | 1 | 2 | Re-新バージョンはいつですか? |
| 5 | 1750 | 1 | 2 | Re-新バージョンはいつですか? |
| 8 | 1822 | 5 | 3 | Re-Re-新バージョンはいつですか? |
| 10 | 1848 | 8 | 4 | Re-Re-新バージョンはいつですか? |
| 6 | 1875 | 1 | 2 | Re-新バージョンはいつですか? |
| 9 | 1942 | 1 | 2 | Re-新バージョンはいつですか? |
| 2 | 2000 | 1 | 納期延長のご相談 | |
| 7 | 2500 | 2 | 2 | 納期延長のご相談 |
| 3 | 3000 | 1 | インフルエンザで寝込んでいます… |
こうした動作を汎用的に考えててみます。まず、新しいメッセージができたとき、コメントもとのメッセージの「id」「レベル」のフィールドの値が分かっているものとします。つまり、新しいメッセージのレコードができあがり、「parent_id」のフィールドは入力されているとします。その上で、新しいメッセージのレコードの「順序数」フィールドを求めます。知りたいのは、どのレコードと、どのレコードの間に入れればいいかということになります。
最初に2つのレコードのうち後のレコードを求めます。前のレコードは「順序数」で並べ替えたときの後のレコードの1つ前で求める事ができるので、後のレコードを求めることがポイントになります。この後のレコードですが、テーブルから「レベル」が(メッセージの「レベル」)の値よりも小さなレコードを検索し、かつ、「id」が新しいメッセージの「parent_id」のレコードの「順序数」より大きなレコードを探します。そして、その中で最小の「順序数」を持つレコードが、後のレコードとなります。ここではその「順序数」が分かればいいことになります。これを、SQLっぽい手法で記載すると次のようになります。
NEWMSG_PID = 新しいメッセージのコメント元の「id」フィールドの値(新しいメッセージの「parent_id」の値) NEWMSG_LEVEL = (SELECT レベル FROM メッセージテーブル WHERE id=NEWMSG_PID)+1; PARENT_ORD = SELECT 順序数 FROM メッセージテーブル WHERE id=NEWMSG_PID; ORD_AFTER = SELECT MIN(順序数) FROM メッセージテーブル WHERE レベル<NEWMSG_LEVEL AND 順序数>PARENT_ORD; ORD_BEFORE = SELECT MAX(順序数) FROM メッセージテーブル WHERE 順序数<ORD_AFTER; NEWMSG_ORD = (ORD_AFTER + ORD_BEFORE)/2;
実際に、前のテーブルの状態で、前述のSQL式を適用して、新しいメッセージの「順序数」フィールドの値を求めてみます。以下、いくつかのパターンとして、元になるメッセージを仮定して数値を求めていますが、この順番にメッセージを追加しているのではなく、前のテーブル内容の状態で、それぞれのメッセージにコメントを付けるという状況を想定しています。
id=1にコメントを付けるとき NEWMSG_PID = 1 NEWMSG_LEVEL = (SELECT レベル FROM メッセージテーブル WHERE id=1)+1; → 2 PARENT_ORD = SELECT 順序数 FROM メッセージテーブル WHERE id=1; → 1000 ORD_AFTER = SELECT MIN(順序数) FROM メッセージテーブル WHERE レベル<2 AND 順序数>1000; → 2000 ORD_BEFORE = SELECT MAX(順序数) FROM メッセージテーブル WHERE 順序数<2000; → 1942 NEWMSG_ORD = (2000 + 1942)/2; → 1971
| id | 順序数 | parent_id | レベル | タイトル(レベルに応じたインデント付き) |
|---|---|---|---|---|
| 1 | 1000 | 1 | 新バージョンはいつですか? | |
| 4 | 1500 | 1 | 2 | Re-新バージョンはいつですか? |
| 5 | 1750 | 1 | 2 | Re-新バージョンはいつですか? |
| 8 | 1822 | 5 | 3 | Re-Re-新バージョンはいつですか? |
| 10 | 1848 | 8 | 4 | Re-Re-新バージョンはいつですか? |
| 6 | 1875 | 1 | 2 | Re-新バージョンはいつですか? |
| 9 | 1942 | 1 | 2 | Re-新バージョンはいつですか? |
| 11 | 1971 | 1 | 2 | Re-Re-新バージョンはいつですか? |
| 2 | 2000 | 1 | 納期延長のご相談 | |
| 7 | 2500 | 2 | 2 | 納期延長のご相談 |
| 3 | 3000 | 1 | インフルエンザで寝込んでいます… |
id=4にコメントを付けるとき NEWMSG_PID = 4 NEWMSG_LEVEL = (SELECT レベル FROM メッセージテーブル WHERE id=4)+1; → 3 PARENT_ORD = SELECT 順序数 FROM メッセージテーブル WHERE id=4; → 1500 ORD_AFTER = SELECT MIN(順序数) FROM メッセージテーブル WHERE レベル<3 AND 順序数>1500; → 1750 ORD_BEFORE = SELECT MAX(順序数) FROM メッセージテーブル WHERE 順序数<1750; → 1500 NEWMSG_ORD = (1750 + 1500)/2; → 1625
| id | 順序数 | parent_id | レベル | タイトル(レベルに応じたインデント付き) |
|---|---|---|---|---|
| 1 | 1000 | 1 | 新バージョンはいつですか? | |
| 4 | 1500 | 1 | 2 | Re-新バージョンはいつですか? |
| 12 | 1625 | 4 | 3 | Re-Re-Re-新バージョンはいつですか? |
| 5 | 1750 | 1 | 2 | Re-新バージョンはいつですか? |
| 8 | 1822 | 5 | 3 | Re-Re-新バージョンはいつですか? |
| 10 | 1848 | 8 | 4 | Re-Re-新バージョンはいつですか? |
| 6 | 1875 | 1 | 2 | Re-新バージョンはいつですか? |
| 9 | 1942 | 1 | 2 | Re-新バージョンはいつですか? |
| 11 | 1971 | 1 | 2 | Re-Re-新バージョンはいつですか? |
| 2 | 2000 | 1 | 納期延長のご相談 | |
| 7 | 2500 | 2 | 2 | 納期延長のご相談 |
| 3 | 3000 | 1 | インフルエンザで寝込んでいます… |
id=9にコメントを付けるとき NEWMSG_PID = 9 NEWMSG_LEVEL = (SELECT レベル FROM メッセージテーブル WHERE id=9)+1; → 3 PARENT_ORD = SELECT 順序数 FROM メッセージテーブル WHERE id=9; → 1942 ORD_AFTER = SELECT MIN(順序数) FROM メッセージテーブル WHERE レベル<3 AND 順序数>1942; → 1971 ORD_BEFORE = SELECT MAX(順序数) FROM メッセージテーブル WHERE 順序数<1971; → 1942 NEWMSG_ORD = (1971 + 1942)/2; → 1966
| id | 順序数 | parent_id | レベル | タイトル(レベルに応じたインデント付き) |
|---|---|---|---|---|
| 1 | 1000 | 1 | 新バージョンはいつですか? | |
| 4 | 1500 | 1 | 2 | Re-新バージョンはいつですか? |
| 12 | 1625 | 4 | 3 | Re-Re-Re-新バージョンはいつですか? |
| 5 | 1750 | 1 | 2 | Re-新バージョンはいつですか? |
| 8 | 1822 | 5 | 3 | Re-Re-新バージョンはいつですか? |
| 10 | 1848 | 8 | 4 | Re-Re-新バージョンはいつですか? |
| 6 | 1875 | 1 | 2 | Re-新バージョンはいつですか? |
| 9 | 1942 | 1 | 2 | Re-新バージョンはいつですか? |
| 13 | 1966 | 9 | 3 | Re-Re-Re-新バージョンはいつですか? |
| 11 | 1971 | 1 | 2 | Re-Re-新バージョンはいつですか? |
| 2 | 2000 | 1 | 納期延長のご相談 | |
| 7 | 2500 | 2 | 2 | 納期延長のご相談 |
| 3 | 3000 | 1 | インフルエンザで寝込んでいます… |
id=8にコメントを付けるとき NEWMSG_PID = 8 NEWMSG_LEVEL = (SELECT レベル FROM メッセージテーブル WHERE id=8)+1; → 4 PARENT_ORD = SELECT 順序数 FROM メッセージテーブル WHERE id=8; → 1822 ORD_AFTER = SELECT MIN(順序数) FROM メッセージテーブル WHERE レベル<4 AND 順序数>1822; → 1875 ORD_BEFORE = SELECT MAX(順序数) FROM メッセージテーブル WHERE 順序数<1875; → 1848 NEWMSG_ORD = (1875 + 1848)/2; → 1861
| id | 順序数 | parent_id | レベル | タイトル(レベルに応じたインデント付き) |
|---|---|---|---|---|
| 1 | 1000 | 1 | 新バージョンはいつですか? | |
| 4 | 1500 | 1 | 2 | Re-新バージョンはいつですか? |
| 12 | 1625 | 4 | 3 | Re-Re-Re-新バージョンはいつですか? |
| 5 | 1750 | 1 | 2 | Re-新バージョンはいつですか? |
| 8 | 1822 | 5 | 3 | Re-Re-新バージョンはいつですか? |
| 10 | 1848 | 8 | 4 | Re-Re-新バージョンはいつですか? |
| 14 | 1861 | 8 | 4 | Re-Re-Re-新バージョンはいつですか? |
| 6 | 1875 | 1 | 2 | Re-新バージョンはいつですか? |
| 9 | 1942 | 1 | 2 | Re-新バージョンはいつですか? |
| 13 | 1966 | 9 | 3 | Re-Re-Re-新バージョンはいつですか? |
| 11 | 1971 | 1 | 2 | Re-Re-新バージョンはいつですか? |
| 2 | 2000 | 1 | 納期延長のご相談 | |
| 7 | 2500 | 2 | 2 | 納期延長のご相談 |
| 3 | 3000 | 1 | インフルエンザで寝込んでいます… |
ただし、この方法でうまく計算できない場合が発生します。この場合だと、id=3のメッセージにコメントを付ける場合、ORD_AFTERの結果はNULLつまりレコードなしになります。その場合、結果的には「最大の順序数より大きな数」を新しいレコードの「順序数」フィールドに入れればいいことになります。テーブルの中の最大の「順序数」と、「順序数」フィールドで扱える最大の数値の中間値というのが数学的には良い定義っぽいですが、結果的には最大の「順序数」に1000を加えた値のような適当な数値でもあまり問題はないと言えるでしょう。
続いて、レベル=1のメッセージを追加する場合を考えてみます。その場合でも適切な「順序数」を設定しないといけません。こうしたメッセージは、ここまでは暗黙の了解として「下へ」続けられるということになっていますが、現実にも下に続けるか、あるいは新しいメッセージはいちばん最初に付けるのかどちらかということになるかと思います。下に続けるのであれば、テーブルの中の最大の「順序数」よりも大きな値を設定すればよく、逆に前に付けるのなら最小の「順序数」よりも小さな数を割り当てればいいでしょう。さきほどのid=3の場合と同様、たとえばプラス1000とかマイナス1000のような値で指定してやれば、多くの場合は問題はないと思われます。トップレベルのものはたとえば投稿した順序あるいはその逆順にしたいということもあるかもしれませんが、コメントについては投稿順、つまりはコメント順に従って順番に下に並ぶ点では共通でしょう。なので、コメントの「順序数」を決める手法に変わりはありません。なお、レベル=1のメッセージが投稿順あるいは逆順で並べ替えをそれぞれしたいとなると「順序数」フィールドに相当するフィールドを、並べ替えの規則の数だけ用意することになるでしょう。つまり、複数の「順序数」フィールドを用意するということです。
いちばんやっかいなのは、1つ目のメッセージの「順序数」の決め方ですが、これは結論を言えば「0」でいいでしょう。新しいメッセージが下に続くのであれば、最初のメッセージの「順序数」より小さな「順序数」を持つレコードは存在しません。そうなれば、扱える範囲での最小値を指定したいところです。整数フィールドだと、マイナスいくつか…ビット数にも寄りますが、そういう数値を指定するとたくさんの「順序数」に空間ができると思えるところです。ただ、実用的な意味では、「0」にしておけば無難と思われます。
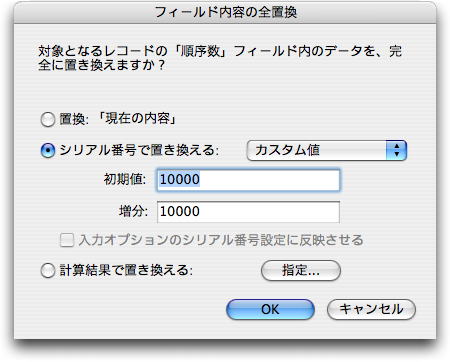
この「順序数」を使う方法は、ある種の限界があります。これまでにサンプルで見て来たテーブルだと、順序数は整数でした。もし、そのフィールドが整数しか扱えないとしたらどうなるでしょうか。仮にid=1とid=2の間の順序数の差は1000です。その間に、つまりid=1のコメントが単に1レベルずつ順番に下がるようにどんどんとコメントされると、11レベル目のコメントを付けたところで、id=1998, 1999, 2000のメッセージが並び、その間にメッセージを割り込ませることができなくなります。つまり、この方法ではいつかは破綻するということです。解決策としては、破綻しそうなときを検知して、「順序数」を入力しなおす事です。「順序数」で並べ替えたときに、このフィールドにたとえば、0でスタートして10000ずつ増やした数値を入れて行く事です。FileMakerでは「全置換」の機能を使えば難しい事ではありませんが、この番号の振り直しをする間は新規にレコードを追加しないようにしなければなりません。なお、FileMakerではさらに言えば数値タイプは整数とは限りません。ここまでは考えやすくするために整数で「順序数」を扱いましたが、浮動小数点数であってもかまわないわけです。人手でのメンテナンスは大変になりますが、通常はそれは不要と考えます。浮動小数点数で扱う限りはそれなりの余裕があると見ていいかと思います。
ここまでに説明した事をふまえて、コメントチェーンを管理するデータベースを作成してみましょう。これまでの説明はFileMakerだからという事情はまったくなく、通常のSQLデータベースであればどれでも実現できる原理です。ここからは、実際にFileMakerで機能を組み込むことにします。
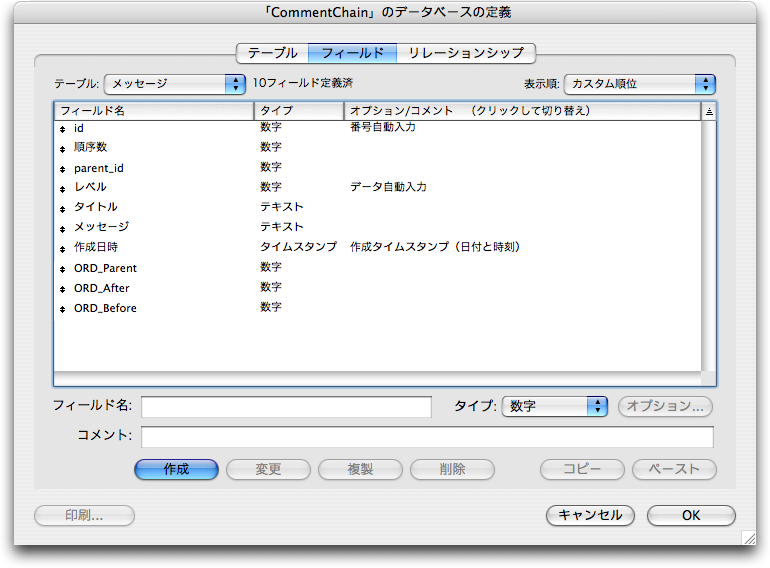
データベースファイル名は「CommentChain.fp7」にしましたが、ファイルは1つだけなので、特に深い意味はありません。その中に「メッセージ」というテーブルを作ります。その1つのテーブルだけでここまで説明しているコメントチェーン化が可能です。「メッセージ」テーブル定義には次のようにフィールドを作ります。「id」フィールドにはシリアル番号を自動的に入力します。「レベル」フィールドには、整数の「1」が自動的に入力されるようにしておきます。「作成日時」は作成した日時のタイムスタンプが自動的に設定されるようにします。ORD_Parent、ORD_After、ORD_Beforeは自分自身の「順序数」を決めるための途中のプロセスを保存しておく数値フィールドです。これらのフィールドは、後から作るスクリプトで埋める感じとなります。
引き続いてリレーションシップの定義を行います。このとき、順序数を決めるプロセスで出て来た手続きをリレーションとして定義します。ここでは4つのリレーションを定義しますが、すべて「メッセージ」テーブル定義をもとにしたテーブルです。その意味ではすべて自己リレーションとなります。いずれのリレーションを作成するときも、「リレーションシップ」のタブで左下のボタンをクリックして、テーブルを作ります。
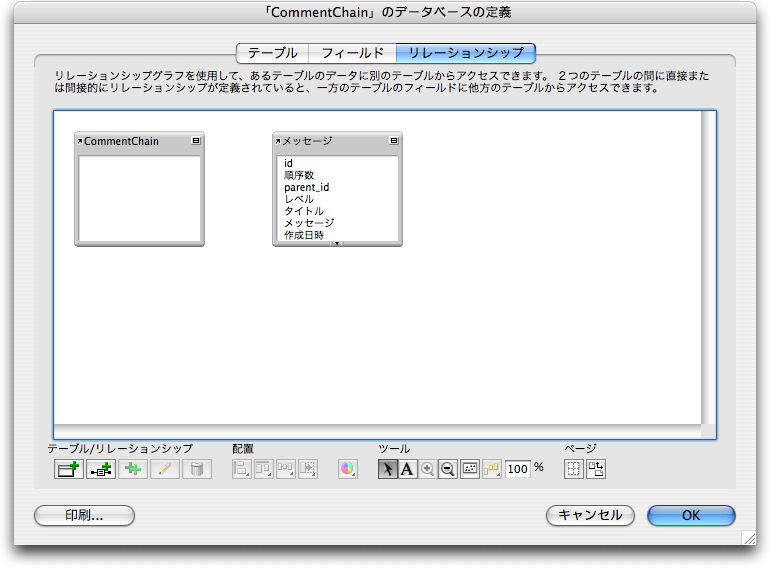
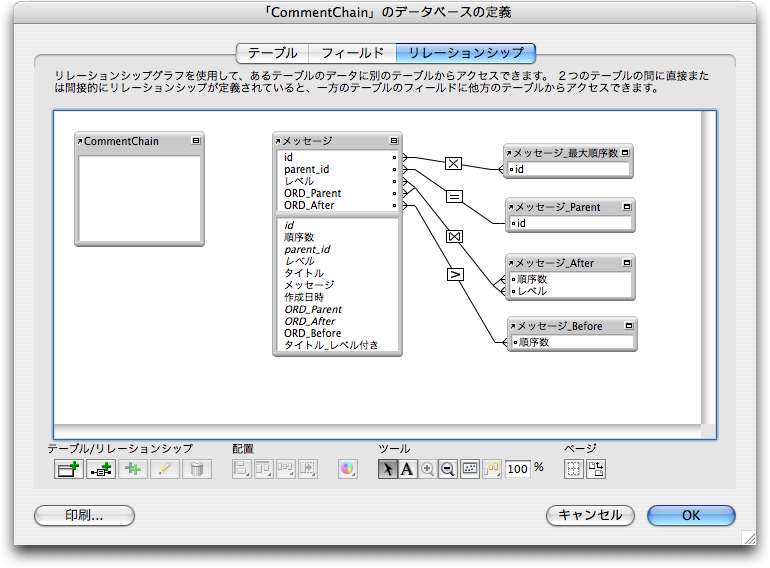
最終的には次のように、4つのリレーションシップを定義します。最初からある「メッセージ」テーブルを基準にして、順序数を求めるためのテーブルを4つ追加します。レイアウトに表示するのは「メッセージ」テーブルとなります。
前に説明した順序数を求めるプロセスを以下にもう一度掲載しますが、それぞれに番号を付けることにします。
(1) NEWMSG_PID = 新しいメッセージのコメント元の「id」フィールドの値(新しいメッセージの「parent_id」の値) (2) NEWMSG_LEVEL = (SELECT レベル FROM メッセージテーブル WHERE id=NEWMSG_PID)+1; (3) PARENT_ORD = SELECT 順序数 FROM メッセージテーブル WHERE id=NEWMSG_PID; (4) ORD_AFTER = SELECT MIN(順序数) FROM メッセージテーブル WHERE レベル<NEWMSG_LEVEL AND 順序数>PARENT_ORD; (5) ORD_BEFORE = SELECT MAX(順序数) FROM メッセージテーブル WHERE 順序数<ORD_AFTER; (6) NEWMSG_ORD = (ORD_AFTER + ORD_BEFORE)/2;
まず、(1)はある意味前提条件です。どのメッセージにコメントするかが分かっているので、そのメッセージの「id」フィールドが得られていて、そこでコメントのレコードを作成するということになります。
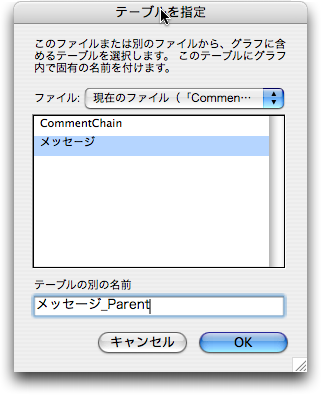
そして、(2)の処理を行います。これは、あるメッセージで自分の親、つまりコメント元になっているメッセージのレコードの「id」フィールドを知りたいということがポイントになります。そこで、「リレーションシップ」を定義するウインドウで、「メッセージ」テーブル定義をもとにした「メッセージ_Parent」テーブルを作ります。そして、「メッセージ」テーブルとリレーションを次のように定義します。つまり、「メッセージ」テーブルから見ると、このリレーションシップによって、コメント元のメッセージを参照できるということになります。
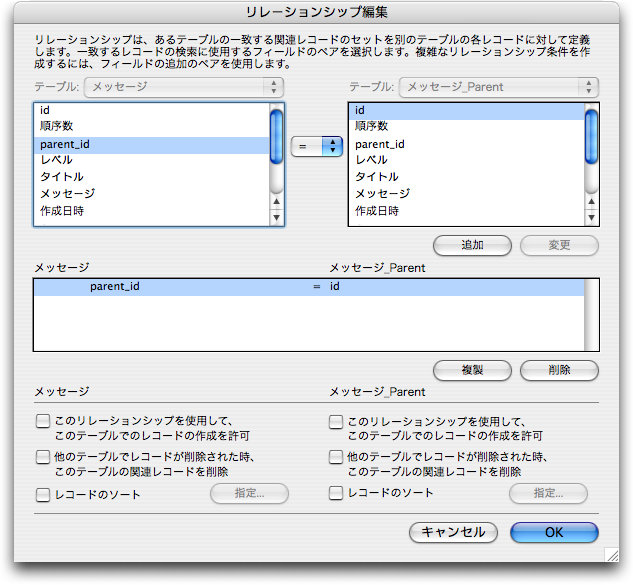
よって、(2)の右側のSELECTはこのリレーションそのものであり、「メッセージ_Parent::レベル」の値を参照して1を加えて自分の「レベル」フィールドにセットすればいいということになります。そして、(3)も同様にこのリレーションシップより、「メッセージ_Parent::順序数」より得られるので、自分の「ORD_Parent」フィールドにセットします。
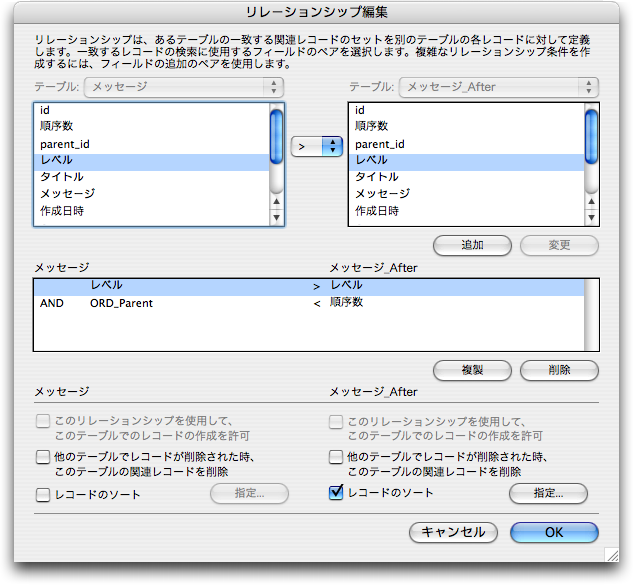
(4)の結果を得るためのリレーションシップを作成します。そのため、「メッセージ」テーブル定義をもとにした「メッセージ_After」を作成し、次の図にあるようにリレーションシップを定義します。つまり、自分のコメント元のメッセージから見て、順序が後でかつレベルがコメント元と同じか低いものであるということです。ここでは自分の「レベル」と比較するので、不等号のみでかまいません。その条件のレコードの順序数が最小のものを取り出すのですが、ここでは最小を取り出すために得られたレコードを「順序数」の順に並べ替えます。並べ替えの設定は右下の「レコードのソート」の「指定」ボタンをクリックして指定します。
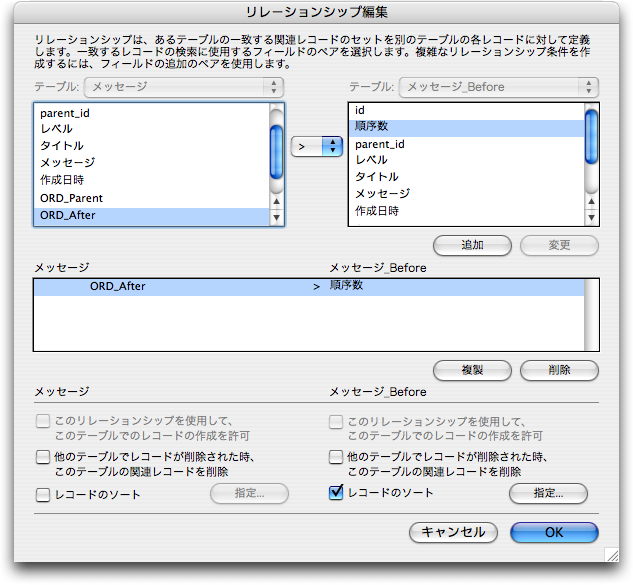
(5)の結果を得るためのリレーションシップには、「メッセージ」テーブル定義をもとにした「メッセージ_Before」を作成して次の図にあるようにリレーションシップを定義します。このリレーションは、「ORD_After」フィールドの値が確定しないと求められません。
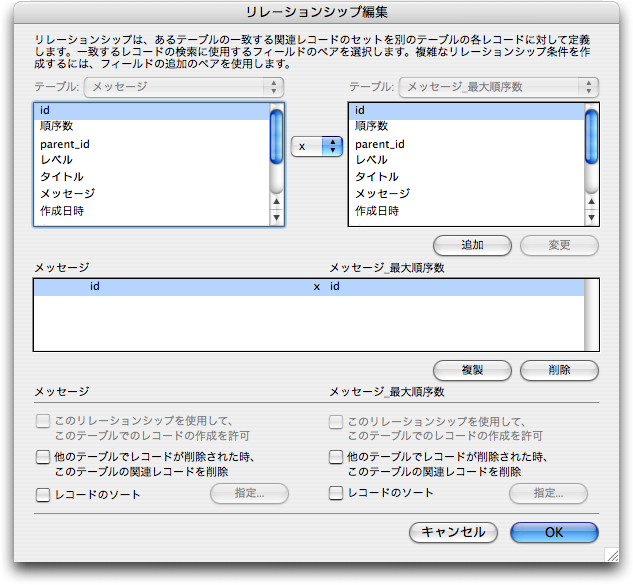
さらに前の「順序数」を求めるプロセスにはありませんが、新たなトップレベル(つまり「レベル」フィールドが1)のメッセージを作るときに、「順序数」の最大値を求める必要があります。そのために、「メッセージ」テーブル同士の直積を作ります。「メッセージ」テーブル定義をもとにした「メッセージ_最大順序数」というテーブルを作り、「id」フィールド同士でリンクを作成します。これにより、「メッセージ」テーブルからすべてのレコードを参照できます。
ここまではまだスクリプトは作成していません。実際にスクリプトを組み立てながら機能を組み込みますが、これまでのところで説明したサンプルとまったく同じように動作させるというところを検証しましょう。まずは、「メッセージ」テーブルを表示するレイアウトをリスト表示にして、次のように、3つのレコードを新たに作成しておきます。ここで、「id」「レベル」フィールドは自動的に入力されますが、「順序数」はまずは手入力で、1000、2000、3000と入力してください。そして、レイアウトのボディパートに「コメント」ボタンを配置します。このコメントボタンをクリックすると「新規レコード作成」というスクリプトが動くようにします。
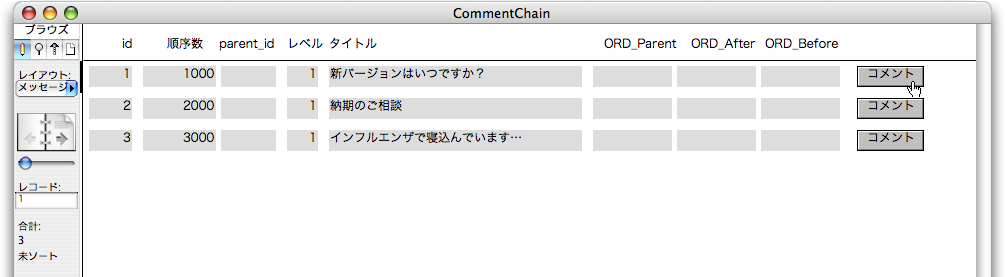
「新規レコード作成」スクリプトは次のように作ります。これはまだ完全なものではありません。コメント元のメッセージにある「タイトル」の内容を変数$originalTitleに設定し、「id」フィールドの値を変数$originalIDに設定をします。そして、新規レコードを作りますが、そのときには新しいレコードが可憐とレコードになっているので、そのレコードの「タイトル」フィールドと「parent_id」フィールドに、コメント元のものをそれぞれ設定しています。もちろん、タイトルには前に「Re-」という文字列を追加しています。

ここまでの動作をまずは確認してみます。ここでは、いちばん最初のid=1のレコードのボディにある「コメント」ボタンをクリックします。すると、新しいレコードが作られますが、「id」フィールドは自動的に「4」と1つ増えた値が設定されます。そして、id=4のレコードの「parent_id」には、「コメント」ボタンをクリックしたレコードの「id」フィールドの値がコピーされています。また、「タイトル」はコメント元のものに「Re-」が付いたものになっています。ここまでで、順序数を決める手順の(1)が完了しています。
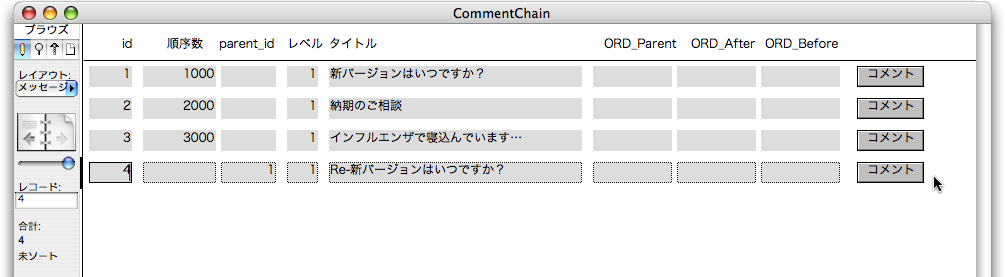
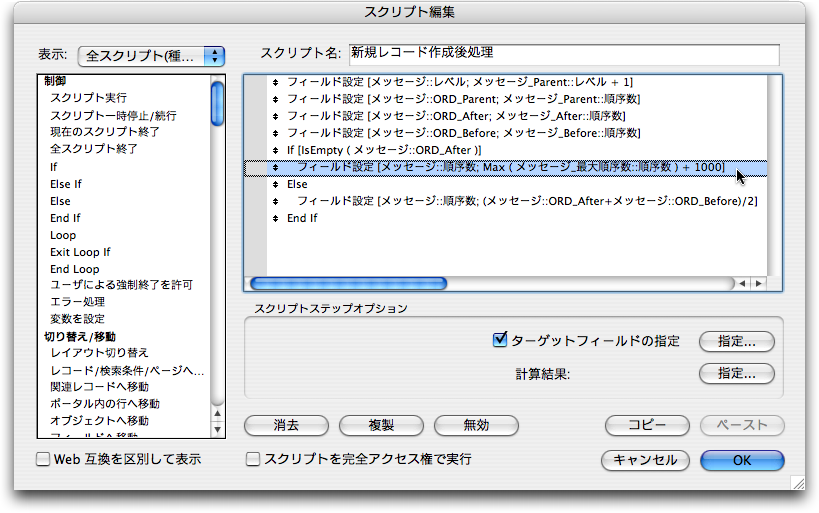
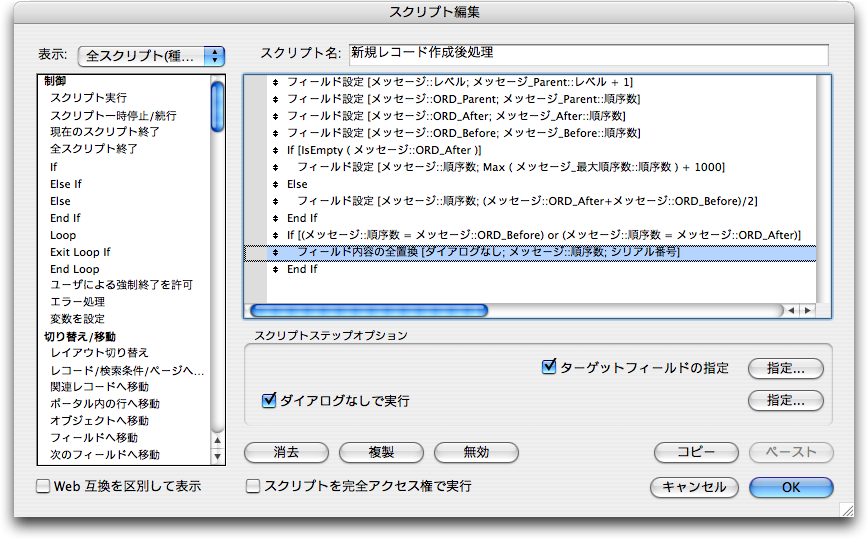
続いて、順序数を決める処理を行うスクリプト「新規レコード作成後処理」を次のように作成します。前に説明した順序数を決めるプロセスの(2)〜(6)に対応した処理が組まれています。なお、(4)はMIN関数、(5)はMAX関数を使うのが適切とも思われますが、もともとリレーション先の関連レコードをソートしてあるので、単にフィールドを参照する事で最初のレコードを取ってくるという動作を利用しています。
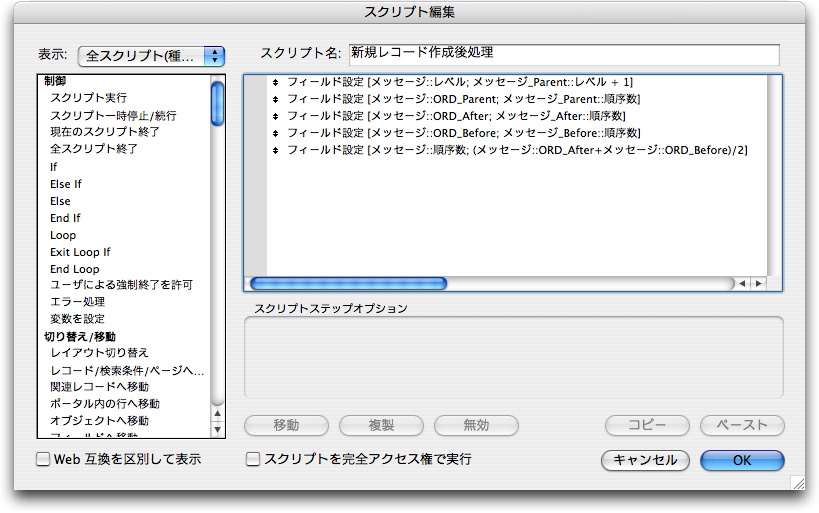
新しく作成されたid=4のレコードをカレントレコードにして、「スクリプト」メニューから「新規レコード作成後処理」を選択してスクリプトを実行します。すると、「レベル」「ORD_Parent」「ORD_After」「ORD_Before」のフィールドがそれぞれ埋まります。そして、「順序数」フィールドは想定通りの結果となっています。ここでは「順序数」フィールドでソートしていないので、並びはコメントチェーン的ではありませんが、これはこの後すぐに対処します。
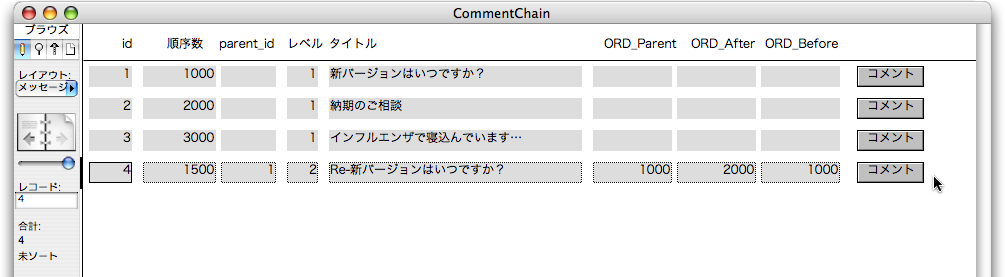
引き続いて、「新規レコード作成」スクリプトを次のように修正します。最後の2つの「スクリプトを実行」「レコードのソート」のステップを追加するだけです。もちろん、「スクリプト実行」は「新規レコード作成後処理」を呼び出すようにします。「レコードのソート」により「順序数」の昇順でソートを行います。
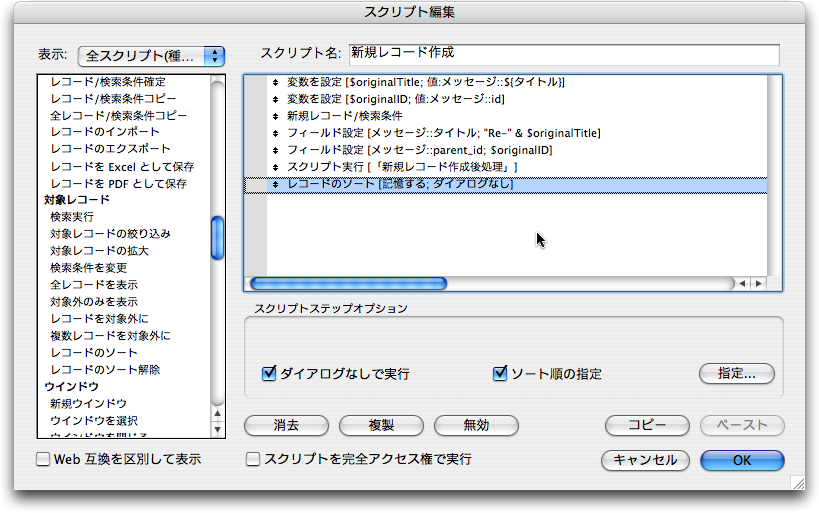
ここで、「新規レコード作成」と「新規レコード作成後処理」を1つにまとめてもいいのですが、このようなアプリケーションを組む場合、「新規レコード作成後処理」は独立している方が何かと便利です。たとえば、コメント先を変えるといった機能を組み込むときには、parent_idを置き換えて「新規レコード作成後処理」を呼び出せば済むようになります。ここで紹介しているだけの機能だとまとめた方がいいように思えるかもしれませんが、モジュール化をしておくことで別の処理を組み立てるときに便利になることもある訳です。
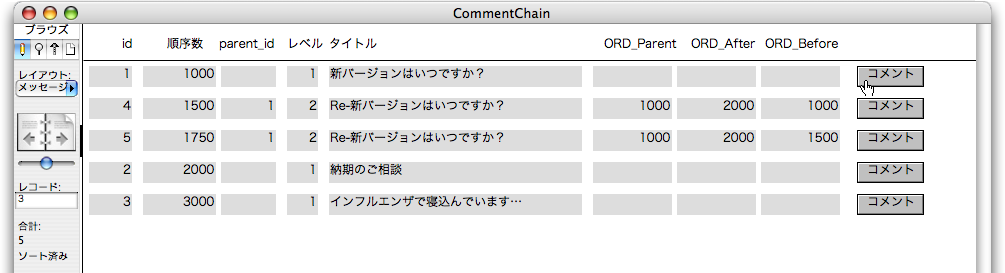
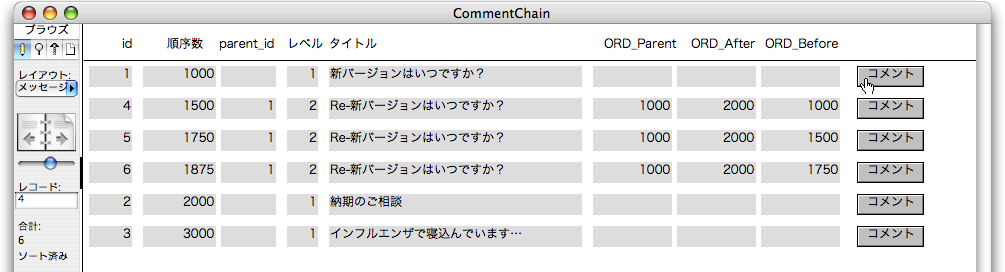
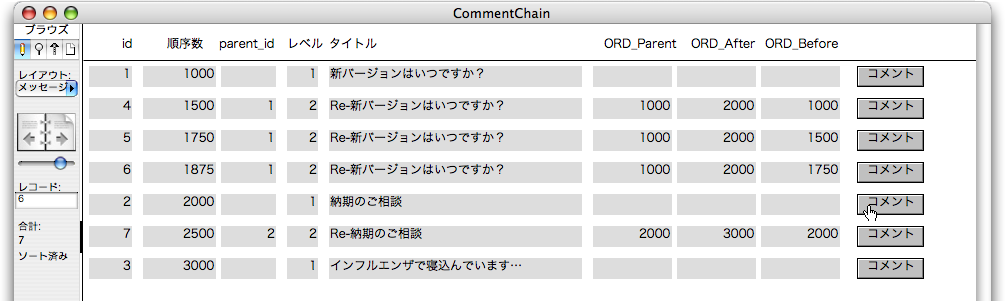
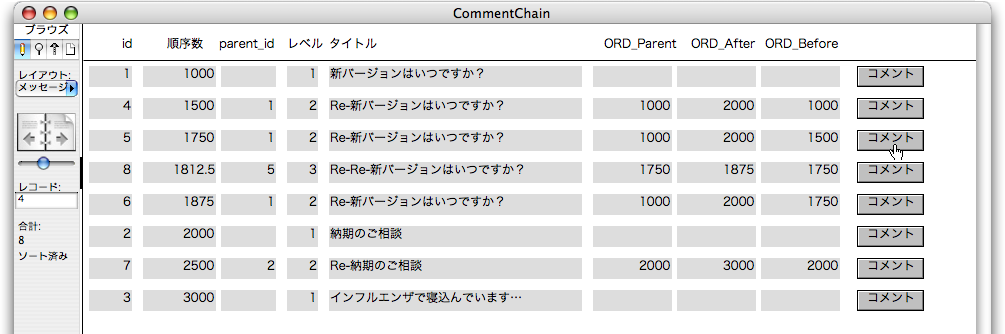
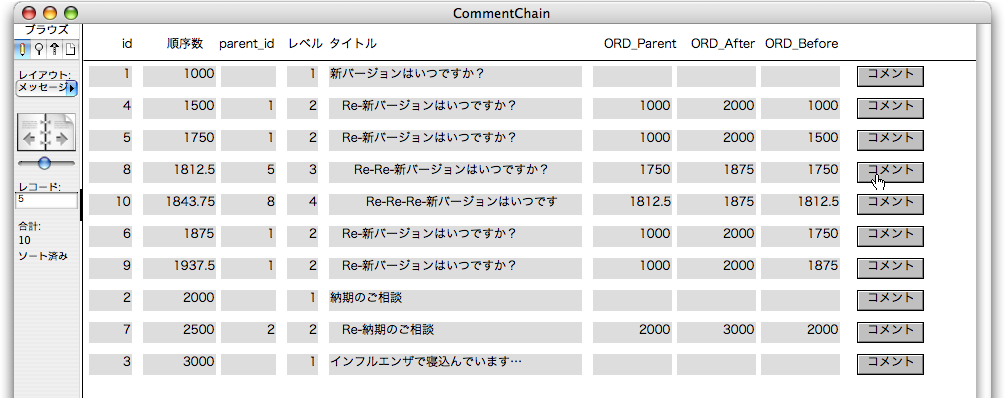
引き続いて動作を検証しましょう。id=1のレコードのボディにある「コメント」ボタンをクリックします。すると、次はid=5のレコードが作られますが、「順序数」には1750が設定され、「順序数」でソートされるので、ここからはコメントチェーンの階層に応じた位置にレコードが並び変わります。図で追いましょう。最初に説明した例のように、順序数が設定されているのが分かります。
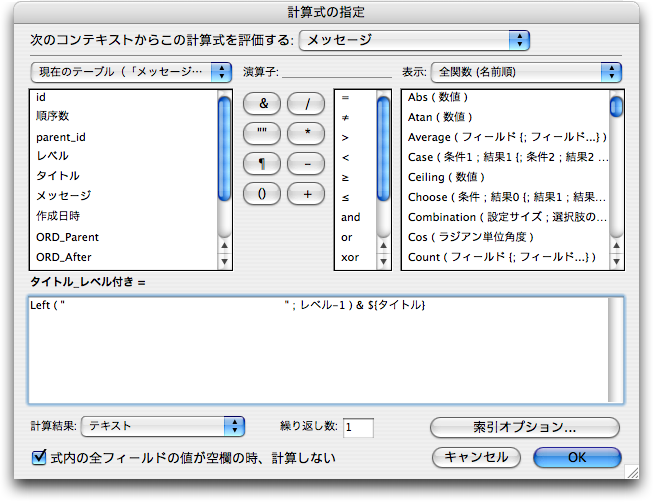
ここで、タイトルをそのまま出しているとレベルが分かりづらいので、レベルに応じたインデント付きのタイトルを表示するための計算フィールド「タイトル_レベル付き」を「メッセージ」テーブル定義に追加します。次のような式ですが、Left関数の最初の文字列は、全角スペースがたくさん並んだものです。つまり、「レベル」フィールドの数に応じてスペースを並べる事でインデントを増やします。なお、カスタム関数ですぐにも作れそうな関数ですが、とりあえずシンプルにこのような式で対処する事にします。計算結果を「テキスト」にすることを忘れないようにしましょう。
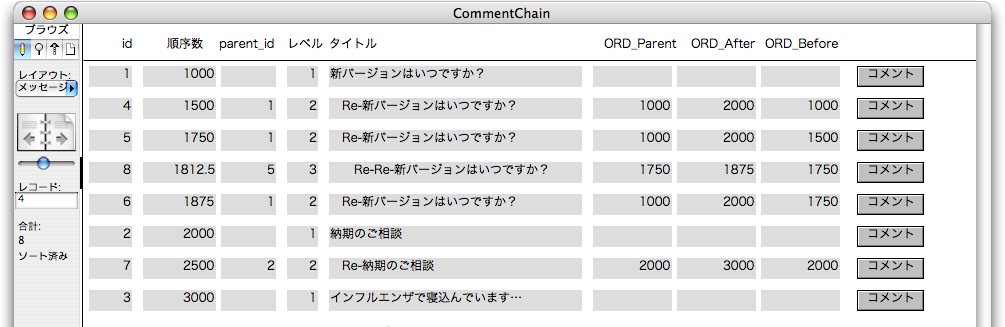
そして、レイアウトの「タイトル」フィールドの代わりに、「タイトル_レベル付き」フィールドを表示すると次のようになります。こうすれば、コメントチェーンらしく見えます。
同様にして、前の例のようにコメントのレコードを作って行きます。
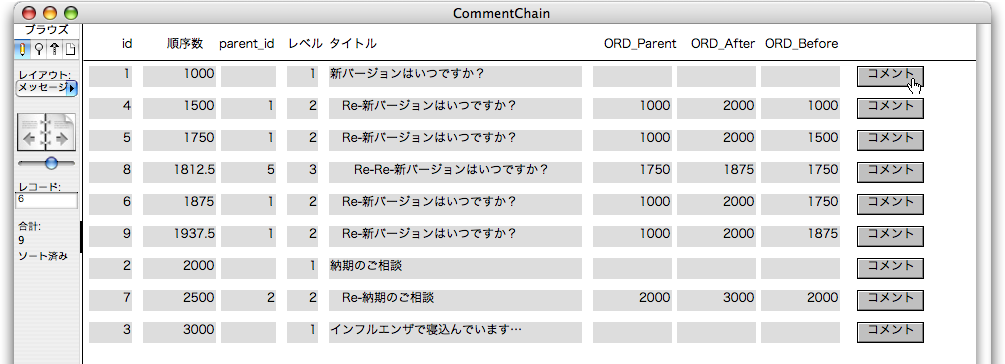
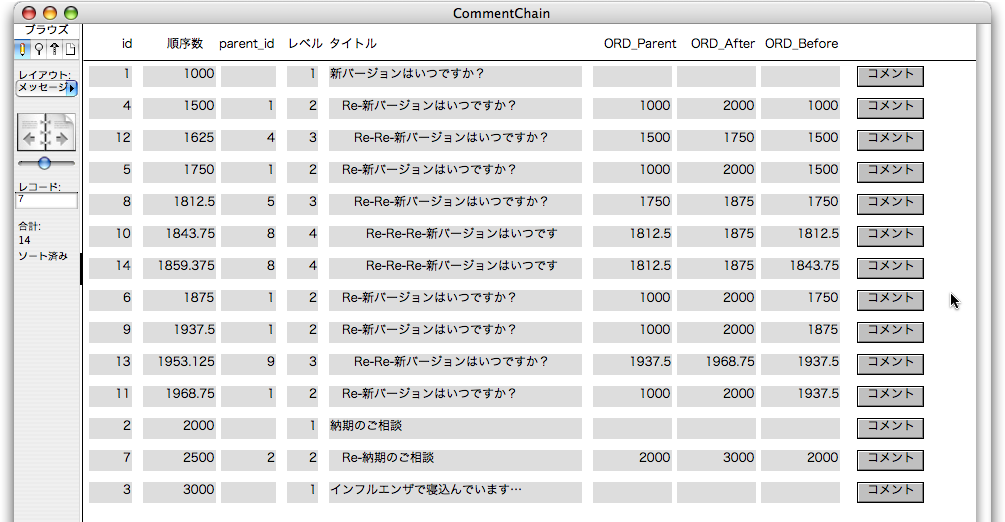
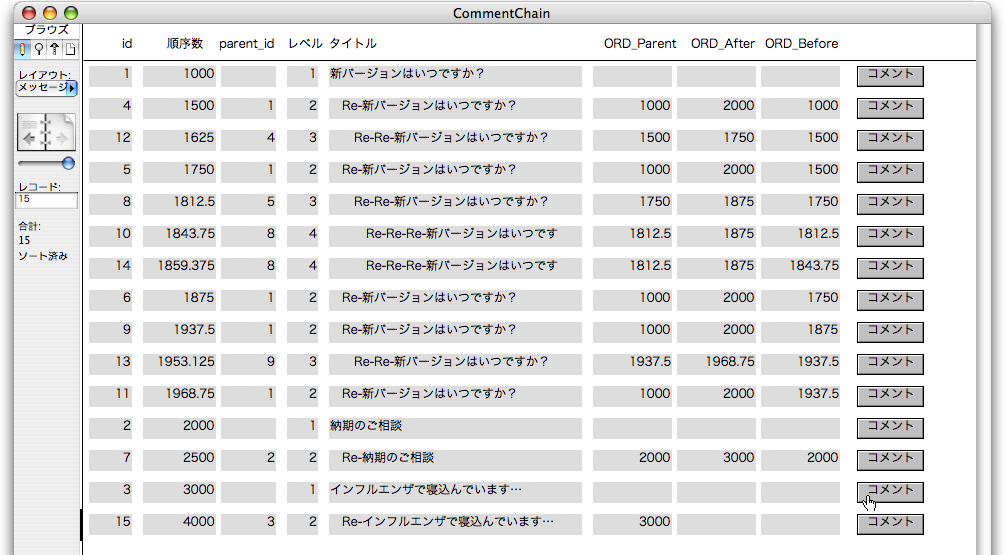
続いて、最後のメッセージにコメントできるようにします。前の状態で言えば、「id=3」のメッセージにコメントする場合です。このとき、ORD_Afterの値が確定しないので、それを判断のよりどころにすれば良いでしょう。スクリプトの「新規レコード作成」を次のように修正します。ステップの(6)において、ORD_Afterの結果がEmptyであれば、そのときの「順序数」の最大値に適当な数、ここでは1000を加えたものを「順序数」とします。ORD_Afterに値が設定されているときは今まで通りです。
実際に「id=3」のレコードのボディにある「コメント」ボタンをクリックしてコメントを作ると、「id=15」のレコードが作成されます。「順序数」は「id=3」のレコードが3000だったので、1000を加えた4000が設定されています。
トップレベルのメッセージを作成できるようにしておく必要があります。ルールはこれまでにも紹介して来た通りですが、作成用に新たにスクリプト「新規トップレベルメッセージ」を次のように作成します。レコードがまったくない場合も考慮して作りました。レコードが全くないということの判断は、「メッセージ_最大順序数」のリレーションシップを利用して、レコードの数をカウントすればいいでしょう。レコードが存在すれば、最大の「順序数」に適当な数としてここでは1000を加えた値を使っています。そうでない場合、最初の順序数は0としています。
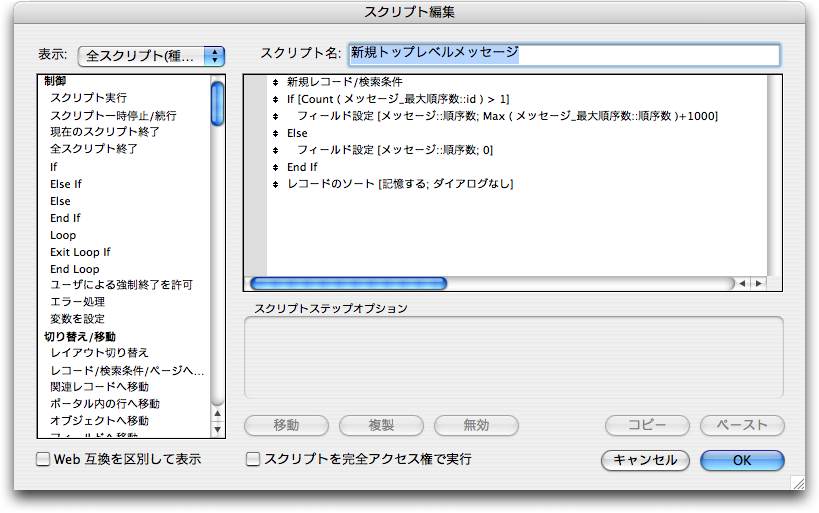
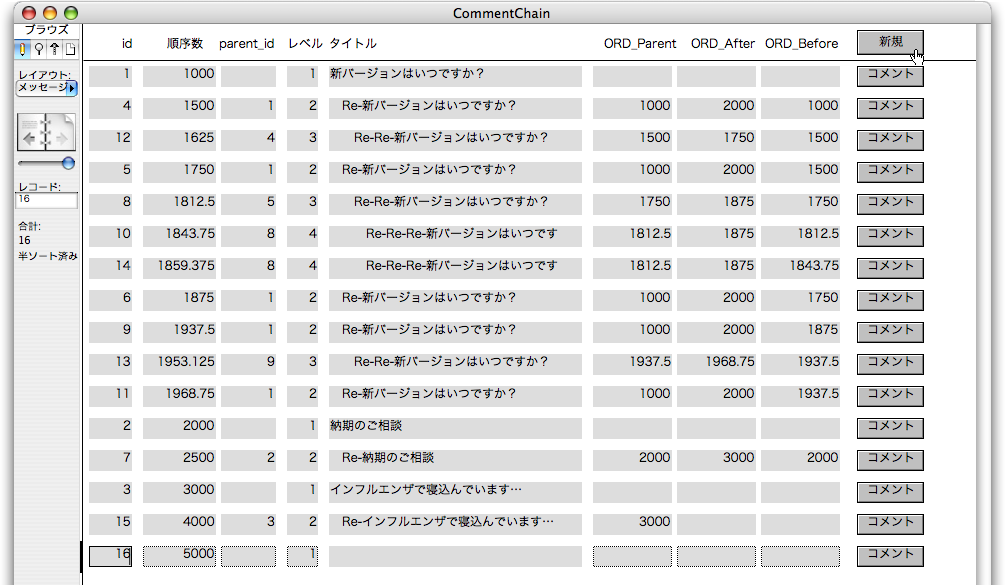
レイアウトのヘッダ部分に図のように、「新規」ボタンを作り、これをクリックすると、「新規トップレベルメッセージ」スクリプトが呼ばれるようにします。図は「新規」ボタンをクリックた結果で「id=16」のトップレベルのメッセージが作成されています。(なお、現在「タイトル_レベル付き」が表示されているので、これは計算フィールドであり入力できません。)
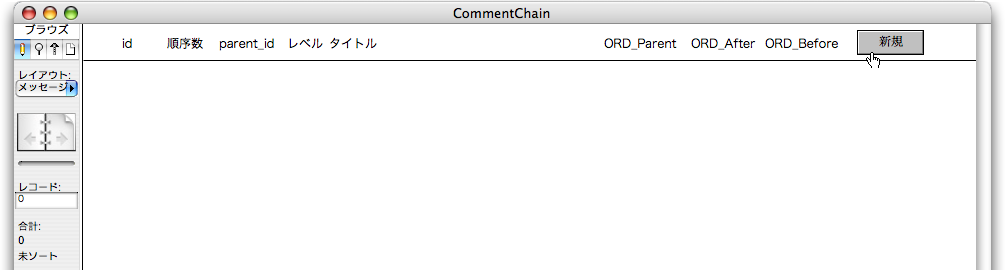
もちろん、ここではレコードを一度全部消去して、「新規」ボタンをクリックして、最初のメッセージが「レベル=1」であり、「順序数=0」であることを確認します。
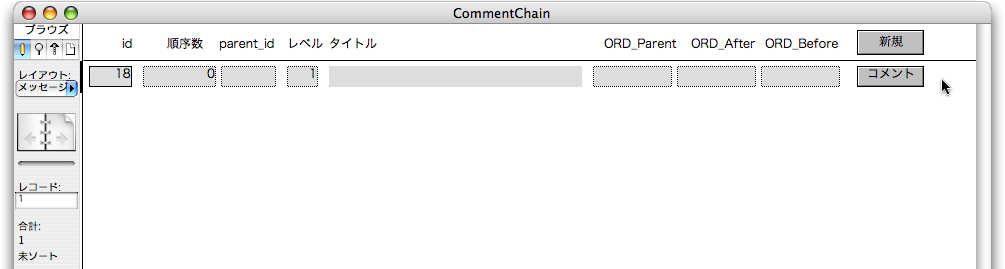
以上で順序数を管理する部分ができました。実際には、メッセージの入力インタフェースや一覧の機能などさまざまな機能をこれから組み込むことになりますが、実際の用途に従った機能を組み込むことになるでしょう。
「順序数」フィールドには、自分が割り込みたい場所の前後の順序数の間の数値を設定するというのがポイントですが、すでに説明したように有限桁の計算を行うコンピュータでは、いつかは「間の数値」を求めることができなくなります。この検出をどうするのかということは、おそらくデータベースによって異なるかと思われますが、FileMakerでは、求めた「順序数」が「ORD_After」と同じになるという傾向があるようです。つまり、=演算子でチェックができるということに他なりません。であれば、「新規レコード作成後処理」スクリプトで「順序数」を決定した後に、次のように「順序数」が「ORD_After」と同じかないしは「ORD_Before」と同じであれば、全置換を行って「順序数」を振り直します。なお、実用的には「全レコードを表示」ステップを使ってすべて表示した上で全置換をするのがいいかと思われます。
なお、メッセージ間を10000ずつ増える順序数にした状態で、コメントのコメントをどんどん作って行った場合ですが、69レベルで振り直しの必要が出ました。 これがメッセージ間が1の場合は55レベルで振り直しになっています。この「何レベルまでOKか」というのは、順序数を管理する数値の精度のビット数と、間隔の数値のビット数でだいたい決まると考えていいでしょう。
コメントチェーンのルールとしては、トップレベルのメッセージは「日付時刻順」となり、コメントについてはコメント元が必ず上に来るということと同レベルのコメントは「日付時刻順」になるということでおおむね説明できていると思います。ここで、トップレベルのメッセージについては、日付時刻順の昇順と降順のいずれの並びもしたくなるところでしょう。一方、コメントの日付時刻順は、トップメッセージの順序に関わらず、おそらく昇順であるのが一般的と思われます。そこを降順と昇順で切り替えたいとは通常は思わないと思われます。
結果的に、この種のコメントチェーンでは、トップレベルのメッセージの日付時刻の昇順、降順の2通りの並びをしたいとなるでしょう。このとき、ここで紹介したやり方を適用するのに、その都度、日付時刻の情報を使うのではなく、「順序数」を2つ管理すればいいでしょう。つまり「降順用順序数」「昇順用順序数」ということです。また、ここでは順序数の管理のために「ORD_Parent」「ORD_After」「ORD_Before」の3つのフィールドを使いましたが、後の2つ「ORD_After」「ORD_Before」については、昇順用と降順用の両方を用意する必要が出てくるでしょう。
ただし、順序数を決めるプロセスにおいては、コメントを作成するのは、昇順も降順も同じ規則でかまいません。ただし、順序数はそれぞれ求める必要があります。昇順時と降順時の違いは、トップレベルのメッセージを作成するときです。昇順の場合はこれまでも出ているように、順序数の最大にプラスアルファすればいいわけです。降順の場合は、逆に順序数の最小値からのマイナスアルファの数値を設定します。ここまでに紹介しているFileMakerのデータベースでは、「メッセージ_最大順序数」とのリレーションを利用する事で、ちょっと名前が矛盾してしまいますが、順序数の最小値も求めることができるようになります。
電子メールの場合は、ヘッダにMessage-IDというフィールドがあって、すべてのメールは一意なIDが付けられているということになっています。実際、Message-IDはほぼ信用していいくらい、しっかり付けられています。いい加減なスパムを除き、すべてのアプリケーションで問題なく付けられていると言えるでしょう。ここで紹介したメッセージはidフィールドをキーにして連番を入力しましたが、電子メールの場合はMessage-IDを利用する事でいいでしょう。ただし、テキストであるので、レコード数が多い場合にはパフォーマンスに注意が必要です。
メールで問題なのは、どのメッセージに対するコメントなのかを機械的に割り出す事は、100%実現していないということです。ヘッダのIn-Reply-Toが付けられている場合にはそれが利用できますが、100%ではありません。Referencesヘッダは複数入ることが多く、決定力に欠けます。なお、In-Reply-ToはRFC的には複数のMessage-IDが入るのもいいのですが、実用上1つのMessage-IDが入っているところしか見た事がなく、これは手がかりになります。筆者の感覚的には50%ほどのメールしか、Message-IDは入っていな気がします。メールソフトが対応していない場合もありますが、企業としてのメールでは特殊なメッセージングシステムを使ったり、CRMでメールのやり取りをする場合も多く、得てしてIn-Reply-Toは無視されがちです。
また、メールの場合、いろいろな理由でコメントを先に受け取ってしまい、その元メッセージを後から受け取る、あるいは処理がそのような順序になってしまいがちでもあります。これはメールの性質上いたしかたないでしょう。
こうした危うい上に成り立っているMessage-IDを、データベースレコードのキーに使うということに、大きな問題があるとも言えなくもありませんが、他にいい手がかりがないので、結果的にMessage-IDを使う事になるでしょう。
結果的にメールをコメントチェーンで管理するには、あるメールを別のメールのコメントにするといった機能を組み込まなければなりません。場合によっては自分のコメントもいっしょに引き連れて移動したいこともあるし、そうじゃないこともあるかもしれません。このように、メンテナンスの機能が非常に複雑になります。意外にお手軽な方法は、順序数を適当にて入力して、レベルを適当に増減させてしまうことです。もちろん、これをいかにうまくさばくようにアプリケーションを作るかとうところは難しいところですが、順序数とレベル以外のものはある意味、後から使うものではありませんので、そこさえメンテナンスしてやればおおむねOKということになるかと思われます。